Nstream Team
29 Aug 2023
Back to insights
The Truth About Streaming Data Application Architectures
Let’s cut to the chase — traditional streaming data application architectures are not feasible for modern business needs because they are complex, resource-intensive, and difficult to scale.
Building and maintaining such architectures is manageable for companies with sophisticated engineering teams — such as Uber, Netflix, or Google — but many enterprises committed to streaming are not getting the most out of their streaming platforms (e.g., Kafka, Pulsar, etc.).
Fortunately, businesses no longer have to dedicate a great deal of time and resources to get the desired value from their streaming data. Here’s the truth about how you can achieve critical real-time use cases using the streaming technologies your business already has in place.
Why are traditional streaming data application architectures challenging for many organizations?
There are two primary reasons why it is difficult to unlock the full value of streaming data with traditional application architectures: 1) Having to own and operate multiple data systems is burdensome; 2) Latency and cost compound as data system requirements increase.
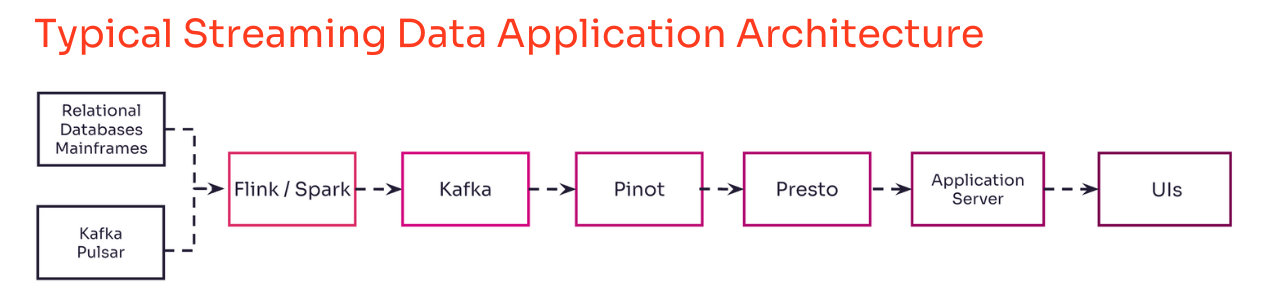
Managing data systems is time-consuming and expensive
With traditional architectures, a wide variety of systems are needed to ingest, store, persist, process, analyze, and visualize data for real-time use. Common systems involved with such architectures include:
- Stream processing frameworks such as Pinot and Presto.
- Additional databases such as Druid, Clickhouse, and MongoDB.
- Additional applications servers such as Spring, NodeJS, and .NET.
- UI frameworks such as Angular and React.
Issues arise when the data engineering team is responsible for designing and maintaining streaming architectures. The application development team trying to create streaming data applications may not fully understand how the underlying streaming technologies work, resulting in the business having to pay a software vendor for each of these data systems or hire Subject Matter Experts (SMEs) for each data system to help with deployment and maintenance.
The truth: Running multiple data systems efficiently and effectively takes a significant amount of resources and time to put in place — from several months to several quarters or even longer. Many businesses “give up” in the middle of this process and fall short of achieving their use case, whether that’s better asset tracking, accessing real-time customer insights, or more effective detection of anomalies such as fraud. The consequences of this decision negatively impact customers, who will continue to have a suboptimal experience, as well as business stakeholders, who are leaving money on the table and opening the enterprise up to greater risk.
Latency and cost compound as data system requirements increase
Traditional streaming data application architectures are stateless, meaning they have to query APIs to get results about relevant state changes. In other words, the context required to surface real-time insights is not automatically updated. Constantly querying databases for external state is inefficient — it drives up latency, as well as costs.
This latency is further compounded as a result of data having to pass through additional downstream data systems. Unnecessary retrieval of high volumes of data that must go through these systems expands time frames beyond the acceptable range (within seconds), defeating the “real-time” purpose of the streaming data applications.
The truth: It’s virtually impossible to achieve true real-time streaming data apps with this traditional architectural approach. For instance, high-value use cases such as personalized offers and recommendations require a large amount of relational information across a number of streams, which cannot be achieved at scale using traditional streaming joins. Unfortunately, it is common for businesses to fall into the trap of spending more and more on their technology stack and dedicating more and more staff time only to see marginal returns in latency reduction and optimization.
How Nstream approaches streaming data app architecture differently
Nstream offers the fastest, most efficient way to build streaming data applications for real-time use cases. Powered by SwimOS, a distributed operating system open-sourced in 2019, the Nstream Platform is the industry’s first open-source, full-stack streaming data application development platform that removes the need for multiple data systems and enables real-time insights and user interfaces (UIs) at network-level latency. Think of it as a way to enjoy the benefits of the backend sophistication and capabilities of companies like Uber or Netflix, but without adding stressful complexity and maintenance requirements.
Say goodbye to managing multiple data systems
Nstream removes the need to adopt and manage multiple data systems, eliminating the prohibitive costs associated with contracting multiple software vendors or hiring additional SMEs. In fact, it takes four times fewer engineering hours to design, build, test, and maintain streaming data applications with Nstream compared to multisystem architectures. That’s a major reason why Nstream boasts a 70% lower total cost of ownership (TCO) than other, more complex approaches.
Say hello to network-level latency and up-to-date context
With Nstream, streaming data is continuously pushed based on relevant state changes rather than queried. This means companies can surface and act on insights when streaming data is available. Continuously pushing and propagating real-world object updates in sync with their data streams also means that context is always kept up to date. This enables real-time observability, live modeling of complex business operations, and responsive decision automation at scale.
Inside the future of streaming data application architectures
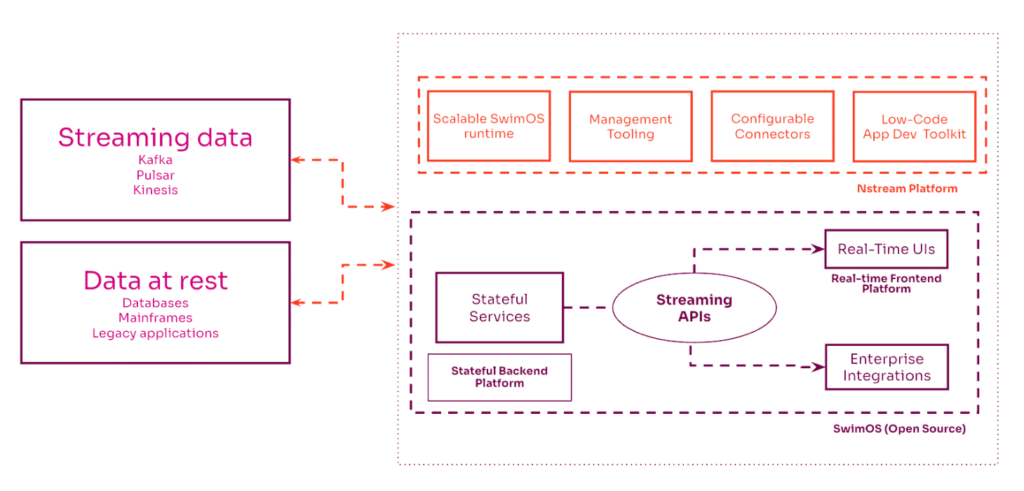
The three innovations that make up the foundation of the Nstream Platform are stateful services, streaming APIs, and real-time UIs:
- Stateful services remember the current state of objects by keeping it in memory and run business logic on real-time data without the need for polling.
- Streaming APIs share relevant context so that systems have all the necessary information for decision-making as soon as possible without asking for it.
- Real-time UIs are automatically updated at network-level latency, providing a live view of what is happening in the real world as events unfold.
In addition to making it easier than ever to configure, deploy, and manage end-to-end streaming data applications for real-time observability, analysis, and automation, Nstream is capable of integrating with other enterprise technologies such as business intelligence tools (e.g., Looker, Tableau), applications (ServiceNow, Twilio), and UI frameworks (Angular, React).
The fastest way to use streaming data for real-time use cases
Nstream is the fastest way to build streaming data applications and unlock the full potential of streaming data. It is a radically effective approach that enables advanced, real-time use cases without investing in a swath of new technologies, extensive employee training, multiple software vendors, or hiring new personnel. Our platform can handle any type of data source, providing the flexibility and scalability required to drive real-time visibility and decision-making.
Interested in learning more about the details of building streaming data apps? Read Using a Kafka Broker to Build Real-time Streaming Applications.